複数人で共有マニュアルや業務ドキュメント、あるいはブログ記事の校正やリライトを共同編集している現場において、最も恐ろしいトラブルの一つが「先祖返り(データの逆行)」です。
誰かが時間をかけて丁寧に修正し、最新版として保存したはずの文章が、別のメンバーが古い手元ファイルをベースに上書き保存したことで過去の状態に戻ってしまう現象は、あらゆる現場で頻発しています。先祖返りは、単純な作業時間の浪費だけでなく、修正したはずの古い誤記や、削除したはずの機密情報が意図せず外部へ公開されてしまうといった重大なコンプライアンスリスクを引き起こします。
この記事を読み進める前に、すでに手元で発生してしまった可能性のある「先祖返り」の箇所を今すぐ突き止め、どの文章が消えてどのテキストが上書きされたかを一瞬で特定したい場合は、以下の完全ブラウザ完結型ツールを直接ご活用ください。
なぜ多発するのか?ドキュメントが先祖返りする主な原因
クラウドストレージやビジネスチャットの普及により、誰もが簡単にファイルを共有・編集できるようになった現代だからこそ、ドキュメントの先祖返りリスクはかえって増大しています。チーム内での変更ルールや運用管理が不十分な場合、主に以下のようなシナリオで先祖返りが発生します。
1. バージョン管理のルールが属人化している
「マニュアル_最新.docx」「マニュアル_最新_修正版.docx」「マニュアル_20260703修正_最終.docx」といった、ファイル名を手動で書き換えるルールで運用している場合、どれが本当の最終成果物であるかの判断が個人の主観に委ねられます。結果として、古いファイルを「最新」と誤認して編集・保存してしまうミスが生まれます。
2. ローカル環境へのファイルダウンロードと再アップロード
クラウド上の共有ドキュメントを一度各自のPCローカル環境にダウンロードして編集し、再度共有サーバーへドラッグ&ドロップで上書き配置する運用を行っている場合、そのダウンロードしてから再アップロードするまでの間に、別のメンバーがオンライン上で加えた細かな修正履歴がすべて上書きされ、闇に葬られます。
3. 同時編集の競合と排他制御のすり抜け
一部のドキュメントツールやテキストエディタでは、複数人が同時に同じファイルを編集した際、システムの自動同期が正常に機能せず、「後に保存した人のデータ」が「先に保存した人のデータ」を強制的に塗りつぶしてしまう仕様があります。これにより、編集画面上では正常に見えていても、保存ボタンを押した瞬間に他人の修正箇所の消失(デッドロックによる損失)が発生します。
上書きミスを確実に防ぐ「文章のバージョン管理」の手順
先祖返りによる実害を最小限に抑え、ドキュメントの先祖返り対策を組織的に仕組み化するためには、ファイルそのものの管理方法を統一することに加え、万が一の衝突時に「どこが巻き戻ったか」をマクロの視点で即座に突き詰める仕組みが不可欠です。
効率的なドキュメント管理を維持するためには、以下のフローを徹底することが推奨されます。
ドキュメントのバージョン管理と差分抽出の運用対比表
| 比較モード / 機能 | 特徴・表示方法 | おすすめの利用シーン |
|---|---|---|
| サイド・バイ・サイド | 左右に文章を並べて表示。変更前後の位置関係を維持。 | 契約書の条文比較・ソースコードのデバッグ |
| インライン表示 | 1つの文章内で、削除を赤・追加を緑で混在表示。 | 記事の校正・メール文面の修正箇所確認 |
| 文字単位比較 | 1文字ずつの細かな違いをハイライト。 | 誤字脱字の特定・送り仮名の修正チェック |
| 単語単位比較 | 単語のまとまりで差分を抽出。 | 英文の添削・翻訳文のブラッシュアップ |
| 空白・改行無視 | スペースや改行の有無を除外して比較。 | フォーマットが異なるデータ同士の純粋な比較 |
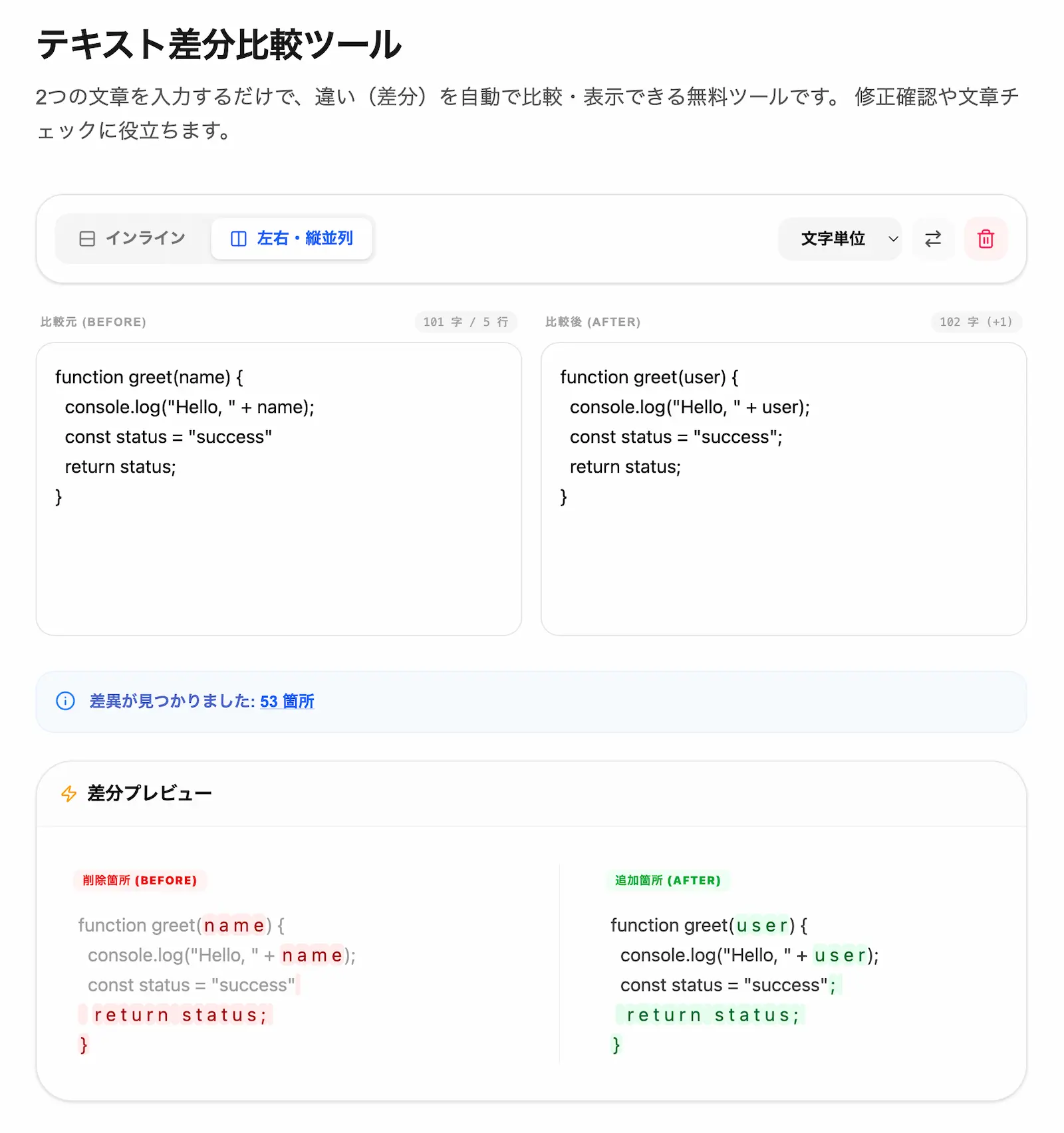
先祖返りが疑われるシーン、あるいは数日前のバックアップファイルと現在のファイルを比較する際は、文章全体の流れを自然な時系列で追跡できる 「インライン表示」 を採用することが極めて効果的です。1つのドキュメントストリームの中で、上書きによって消えてしまった文章(赤色ハイライト)と、新しく追加された文章(緑色ハイライト)が混在表示されるため、どの段階のテキストが巻き戻ってしまったのかを数秒でトラッキングすることが可能になります。
テキスト差分比較ツールに文章を貼り付けて先祖返りの箇所を特定する
大手商用サイトとは違う「完全ローカル処理」による機密情報の絶対保護
マニュアルの改訂、契約書の推敲、社外秘の企画書など、ビジネスの根幹に関わる重要なドキュメント同士を突合させる際、最も慎重にならなければならないのが「テキストデータのセキュリティ担保」です。
インターネット上で無料で使える一般的な文章比較サービスや、大手企業が運営する校正支援クラウドの多くは、ユーザーが入力欄に貼り付けたテキストデータを一度サービス提供元の「外部Webサーバー」へと送信し、サーバーサイドのプログラムで差分(Diff)を計算してブラウザへ結果を返す仕組みをとっています。また、システム改善やAIの学習効率化という目的の下、入力されたテキストの内容をログデータとしてデータベースに蓄積・保存しているケースも少なくありません。
このような「サーバー送信型」の外部サイトに、未公開のプレスリリース、機密情報を含む顧客名簿、あるいは自社独自のソースコードを貼り付ける行為は、通信の傍受やサーバー側でのデータ流出トラブルを引き起こす深刻な情報漏洩リスクに直結します。企業のコンプライアンス規律が厳格化する中で、利便性のために機密を危険に晒す運用は絶対に許容されません。
当サイトが提供するツールは、こうした商用クラウドサービスが抱えるプライバシーの懸念を完全に解消するため、ユーザーの端末内で処理を完結させる 「完全ブラウザ完結設計」 を採用しています。
比較元(Before)と比較後(After)の入力エリアに入力されたすべてのドキュメントテキストは、インターネットを介して外部のサーバーへ送信されることが一切ありません。すべての差分計算と色分けハイライトの処理は、ユーザー自身が今使用しているブラウザの内部(メモリ上)だけで完結します。
さらに、データがデータベースなどの外部記憶装置に残ることもないため、作業を終えてブラウザのタブやページを閉じれば、入力された重要ドキュメントの痕跡はメモリ上から即座に、かつ完全に自動消去されます。
この徹底したクローズド環境があるからこそ、社外秘のドキュメントを扱うプロジェクトマネージャーや、機密保持契約(NDA)に基づく契約書を検証するWebディレクターが、セキュリティポリシーに違反することなく安心して日々の変更点追跡業務を効率化できる強固な信頼性を生み出しています。
チームのドキュメント品質を担保する表記ゆれの自動検収
先祖返りの追跡に加えて、複数人でドキュメントを編集した後に必ず実施すべきなのが、文章全体の表記ゆれ(トンマナ)の検収作業です。
どれだけマニュアルやガイドラインを定義していても、書き手が複数人に分かれると、英数字の全角・半角混在や、アルファベットのケース(大文字・小文字)の揺らぎ、送り仮名の違いといった「目視では見落としがちな微細な差異」が必ずドキュメント内に混入します。
これらを効率的に整え、先祖返りによるトラブルを組織の運用フローから一掃するためには、以下の応用アプローチが役立ちます。
- 複数回にわたる修正履歴から先祖返りを確実に防止する手順 複数人でドキュメントの更新を繰り返す際、古いバージョンの内容で上書きされる先祖返りのトラブルが頻発します。最新の成果物と前々回のバックアップを直接突き合わせ、時系列順の変更点をマクロの視点で追跡することで、修正の逆行を未然に防ぐことが可能になります。
- 大文字・小文字や全角・半角の規則性を揃える表記ゆれ検収 英数字の全角・半角混在や、アルファベットのケース(大文字・小文字)の揺らぎは、単純な目視では検知が困難です。本ツールの詳細ハイライトを活用し、文字種別の置換ルールと組み合わせたマクロ検証を行うことで、文書全体のトンマナを一括で整えることができます。
- MarkdownやCSVなど構造化テキストの差分を正確に読み解くコツ カンマ区切りのデータや、特定の記号で装飾されたマークアップ形式のドキュメントは、表示結果だけでなく生データでの比較が不可欠です。記号やカンマの配置ミスによるフォーマット崩れを特定するため、プレビュー表示に頼らず文字列同士の厳密な対比を行う癖をつけましょう。
人間の集中力や認知限界に依存した手作業の校正チェックを続け、重大な変更点を見落としたままマニュアルを配布したりWebに記事を公開したりするリスクは、デジタルの自動計算を取り入れることで完全に防ぐことができます。
ドキュメントの先祖返りによるデータ損失の恐怖を克服し、チームによる共同編集の成果を常に正確に反映し続けるためにも、完全ローカル型で動作する安全なテキスト対比環境をいつでも呼び出せるよう準備しておくことを強く推奨します。